Positional Encoding Explained: Sinusoidal Embeddings and RoPE (Part 2)
Introduction
In Part 1, we explored three simple approaches to positional encoding. Direct integers, normalized values, and binary vectors.
The most important lesson came from binary encoding. It revealed a multi frequency structure hidden inside position representations. Each bit oscillates at a different rate. Low bits flip rapidly, capturing fine grained position differences. High bits flip slowly, capturing coarse position in the sequence.
The structure was right. The problem was the shape. Square waves jump between 0 and 1 with no in between. Adjacent positions sometimes looked very different in vector space. Neural networks need smooth inputs to learn smooth functions.
Replace the square waves with smooth waves but keeping the multi frequency structure and making it continuous.
In this post, we will cover two approaches:
-
Sinusoidal positional encoding, introduced in the original Transformer paper (Vaswani et al., 2017). It uses sine and cosine waves at geometrically spaced frequencies to give each position a unique, smooth, bounded vector.
-
Rotary Position Embeddings (RoPE), introduced by Su et al. (2021). Instead of adding position to the embedding, it rotates the query and key vectors by their position. This makes relative position evident via the dot product naturally, with no learning required.
Sinusoidal encoding was a great step. But it has a structural limitation in how it mixes position with meaning. RoPE fixes that limitation, and is the method used in nearly every modern large language model today, including LLaMA, Mistral, Gemma, and Phi.
We will build both ideas step by step. Every formula will be derived from scratch. Every design choice will be motivated by a specific problem.
Let us start from exactly where Part 1 left off: the square waves of binary encoding and the two functions that make them smooth.
Idea 4: Sinusoidal Encoding
The Smoothest Periodic Function
The smoothest possible periodic function is the sine wave or cos wave.
A sine wave does not jump. It rises and falls continuously. Adjacent points on the wave are always close to each other in value. Two positions that are near each other will always produce sine values that are near each other.
Compare a square wave and a sine wave at the same frequency:
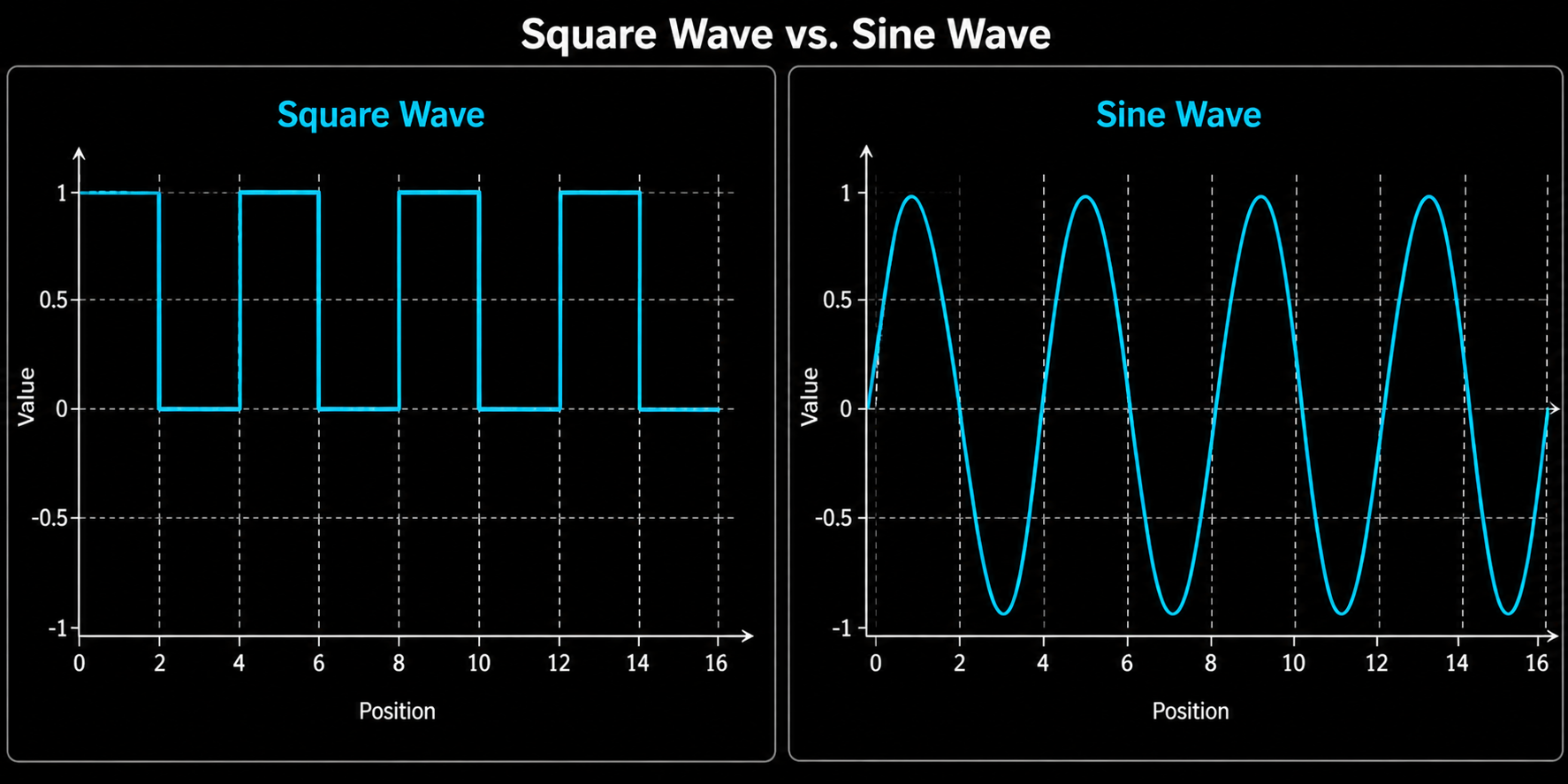
Both waves oscillate at the same rate. Both repeat at the same period. The difference is how they get from low to high. The square wave jumps. The sine wave moves smoothly.
Before we work out the formulas, it helps to actually see what these waves look like in motion.

The animation traces out sine waves at 3 frequencies (dim 1, dim 2, dim 3). As the position advances, the wave moves smoothly through space. There are no sudden jumps. There are no discrete flips. Every step from one position to the next is a continuous change.
Building a Multi Frequency Encoding
If we take inspiration from binary encoding, we want multiple sine waves stacked together. Each one oscillating at a different frequency.
For position $pos$ and dimension index $i$, the most natural starting point is:
\[PE(pos, i) = \sin(pos \cdot \omega_i)\]Where $\omega_i$ is the frequency for dimension $i$.
Different dimensions get different frequencies. Some dimensions oscillate fast, like the LSB in binary. Others oscillate slow, like the MSB.
We now have to answer two questions:
- How do we choose the frequencies $\omega_i$ for each dimension?
- Is using only sine enough, or do we also need cosine?
The original Transformer paper answers both. Each one solves a specific problem.
Let us look at the frequency choice first.
Choosing the Frequencies
We need a range of frequencies. Some should be high, so the encoding can distinguish nearby positions sharply. Some should be low, so the encoding can carry information across long distances without repeating.
The paper uses this formula for the frequency of dimension pair $i$:
\[\omega_i = \frac{1}{10000^{2i/d}}\]Where $d$ is the total dimensionality of the encoding.
Let us see what this gives us.
For dimension pair $i = 0$:
\[\omega_0 = \frac{1}{10000^{0}} = 1\]The wave oscillates rapidly. The value changes meaningfully with every position. This is the “fast bit” of the encoding.
For dimension pair $i = d/2$:
\[\omega_{d/2} = \frac{1}{10000^{1}} = \frac{1}{10000}\]The wave oscillates extremely slowly. It barely changes over thousands of positions. This is the “slow bit” of the encoding.
Between these two extremes, the frequencies decrease smoothly on a geometric scale.
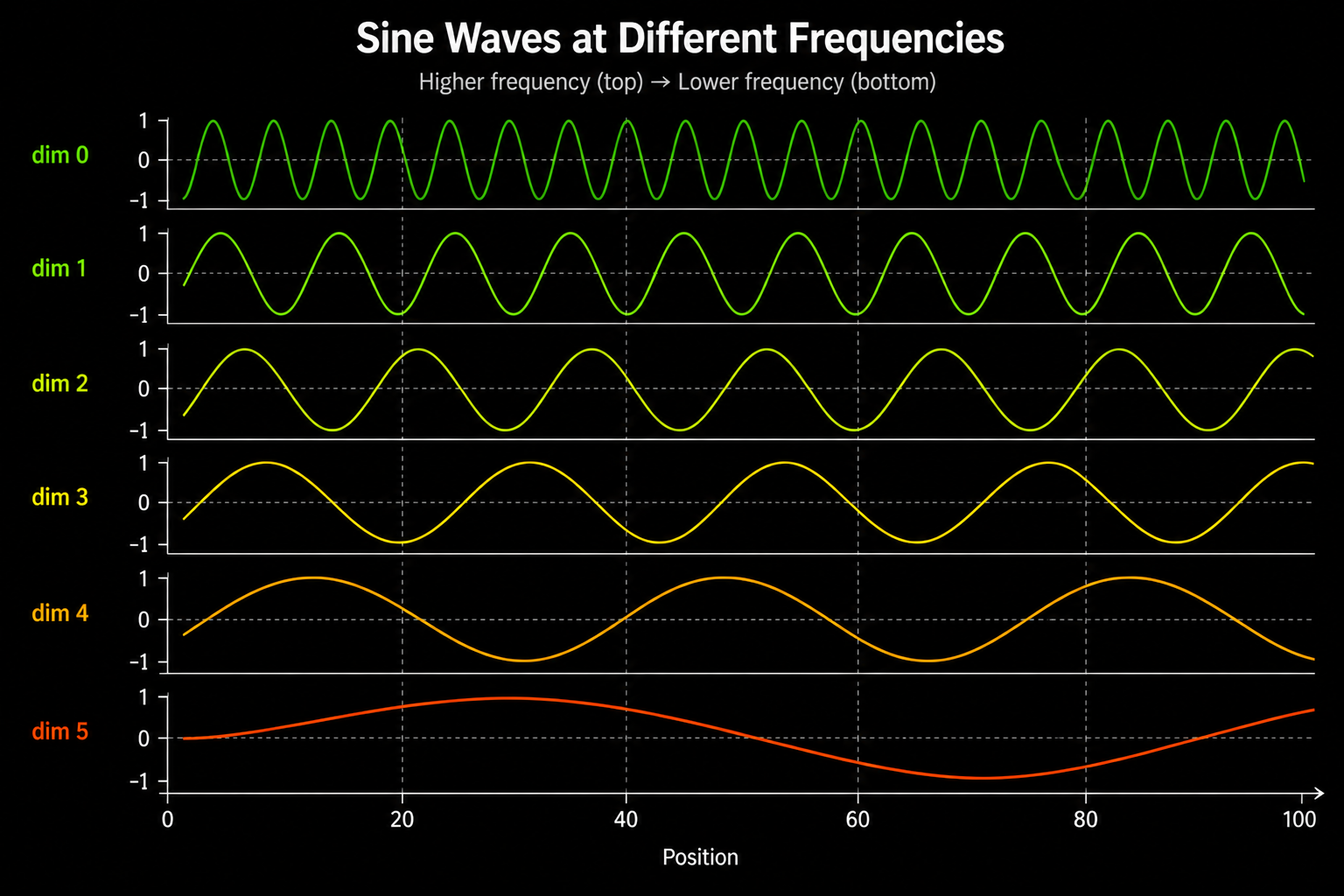
This is the same multi frequency structure we saw in binary encoding. Fast dimensions for fine grained position. Slow dimensions for coarse position. The difference is that every wave is smooth.
The general form:
\[y = \sin(\omega \cdot x)\]Where $\omega$ is the frequency. Larger $\omega$ means the wave oscillates faster. Smaller $\omega$ means it oscillates slower.
To see this concretely, let us look at four sine waves with progressively lower frequencies. Consider x=pos and the number multiplied to the x (pos) be the frequency $\omega$
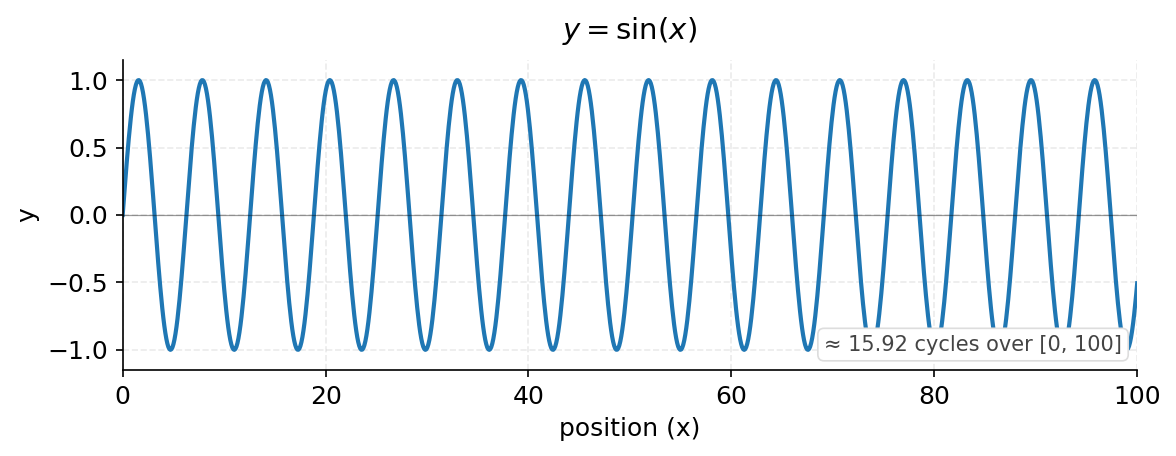
$\sin(x)$
This is the baseline. The wave completes one full cycle every $2\pi$ units. It oscillates rapidly.
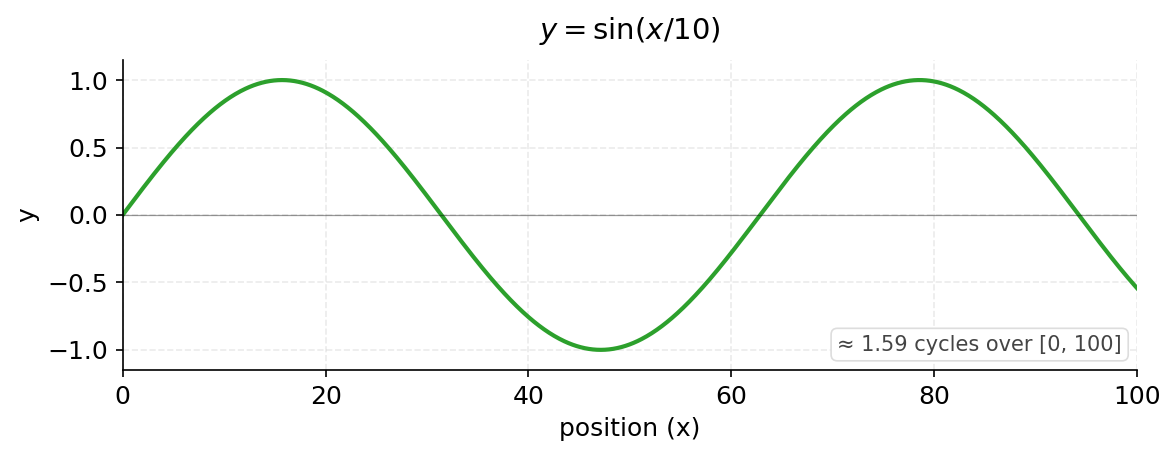
$\sin(x/10)$
Dividing the input by 10 stretches the wave horizontally by a factor of 10. The wave still does the same thing, but it takes 10 times longer to do each cycle. One full cycle now takes about 63 positions.
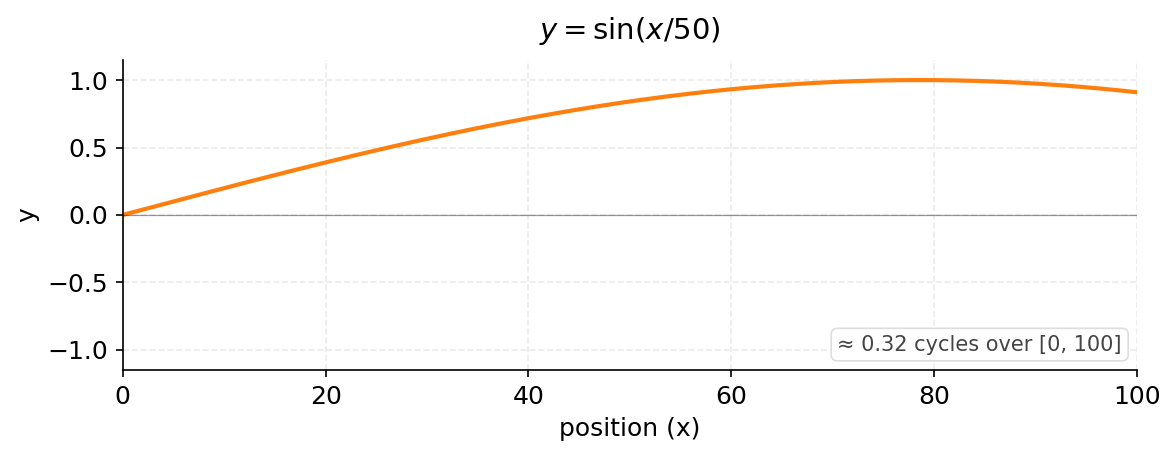
$\sin(x/50)$
Now the wave is very slow. Across 100 positions, we see only about 0.32 cycles. The wave is starting to look like a gentle curve rather than a rapid oscillation.
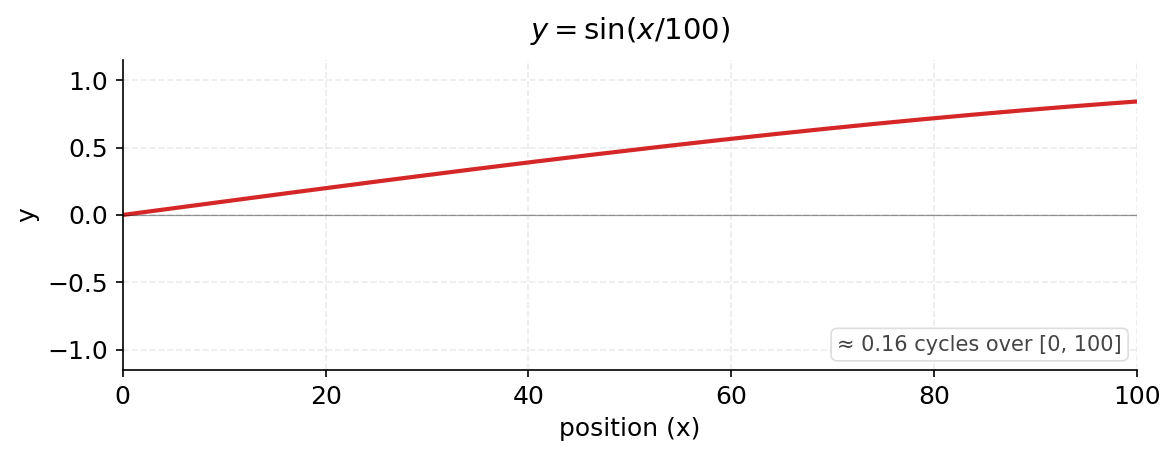
$\sin(x/100)$
At this frequency, we do not even complete one full cycle across 100 positions. The wave is nearly monotonic over the visible range. Adjacent positions look almost identical.
Stacking Them Together
If we stack these four waves on the same axis, we see the spectrum in one view.
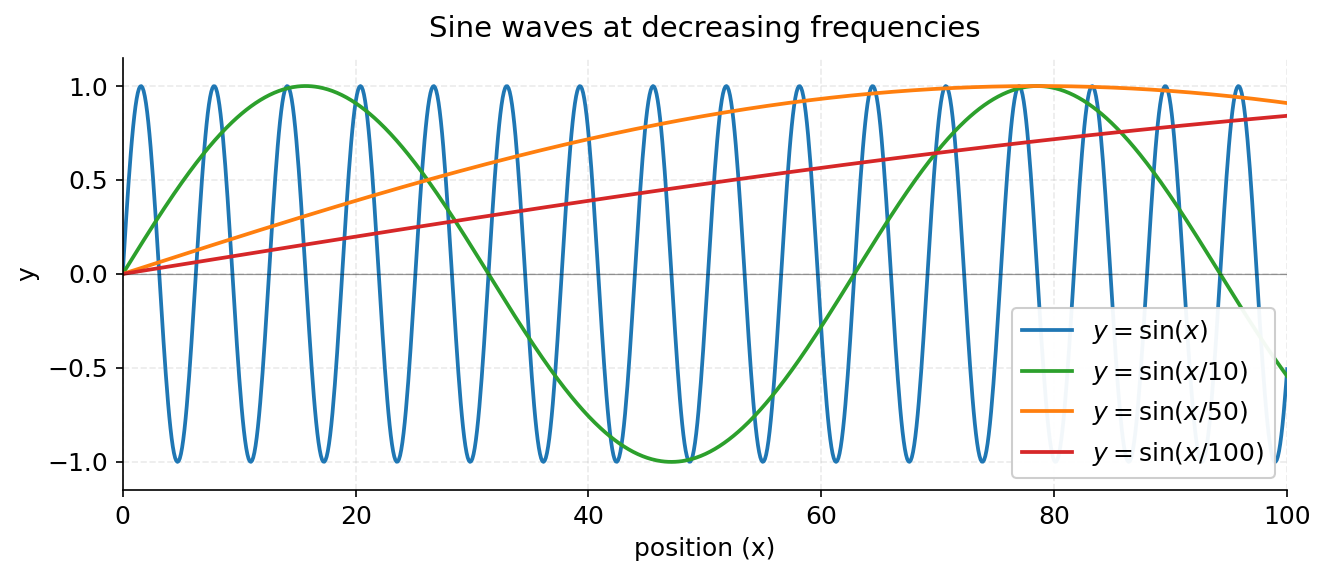
This is the same idea as binary encoding’s stack of square waves, but smooth. Fast waves capture fine grained position changes. Slow waves capture coarse, sequence wide position.
Each wave tells the model a different thing about where a token sits.
This gives us the visual intuition. The actual transformer formula controls this spectrum through the choice of base 10000. Let us see why.
Why 10000?
The number 10000 looks arbitrary. but its not.
It controls the range of frequencies. With a base of 10000, the slowest wave completes a full cycle every $2\pi \times 10000 \approx 62{,}832$ positions. This means within any reasonable sequence length, the slow dimensions never repeat. Every position gets a unique encoding.
let us plot the same encoding with three different base values: 100, 10000, and 100 million.
For each base, we will look at four different dimension indices to see how the wave behaves across positions 0 to 1000.
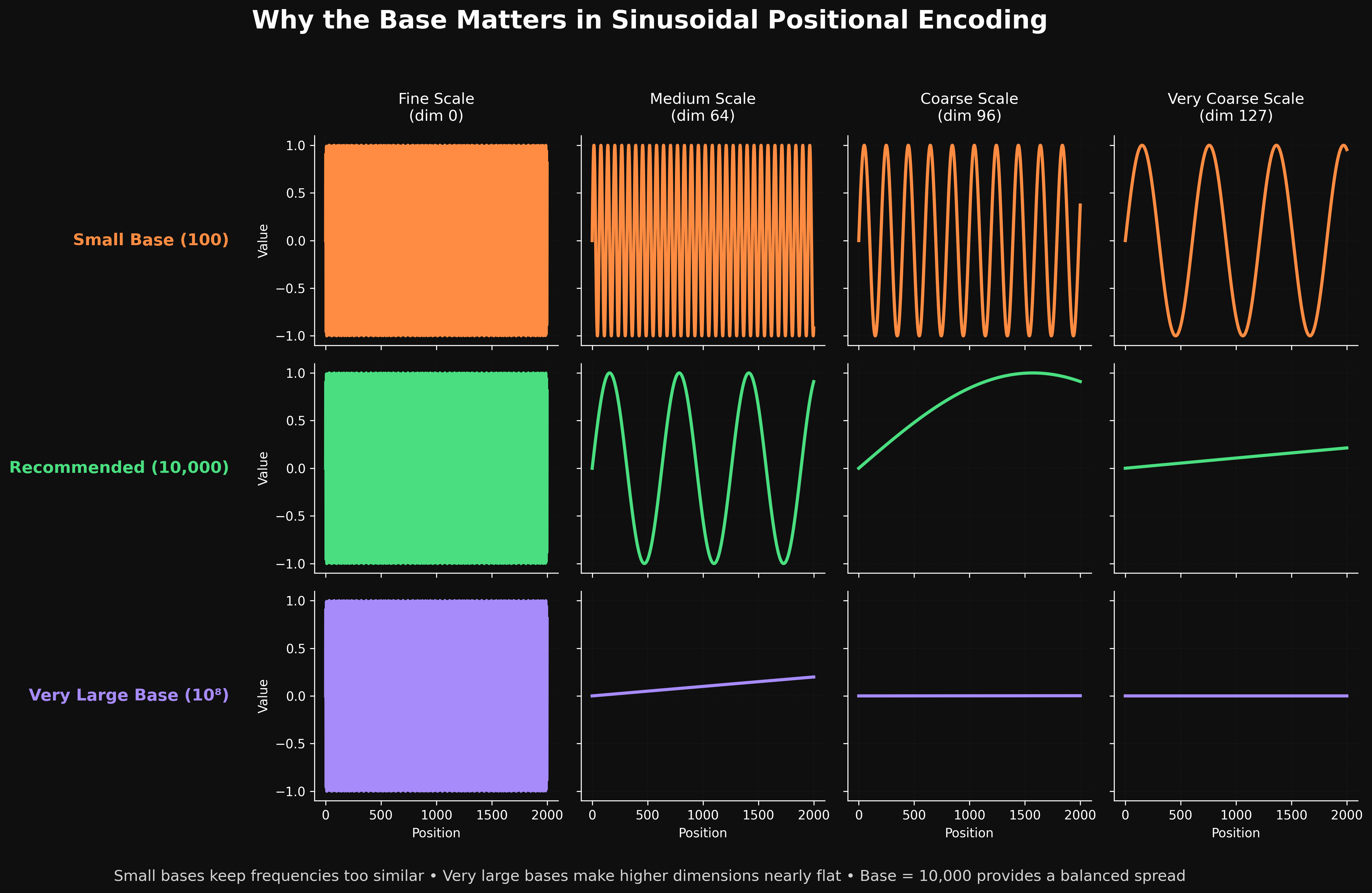
Each row shows one base value. Each column shows one dimension index. The top row uses base 100. The middle row uses base 10000. The bottom row uses base 100 million.
Base = 100 (top row)
Look at the four columns left to right.
-
dim 0 oscillates rapidly. This is expected. Every base produces a fast wave at dim 0.
-
dim 64 still oscillates a lot. Across 1000 positions, you see about good number of full cycles. The wave is far from slow.
-
dim 96 also oscillates clearly. About good number of cycles across 1000 positions.
-
dim 127 (the slowest dimension) still completes few full cycles in 1000 positions.
This is the problem with a small base. Even the slowest dimensions oscillate within the visible range. The waves repeat. Two positions far apart can produce identical encodings in every dimension simultaneously. The model loses its ability to tell distant positions apart.
A base of 100 spreads the frequency spectrum too narrowly. Everything moves too fast.
Base = 10000 (middle row)
This is the actual choice from the Transformer paper. Look at how the behavior changes.
-
dim 0 still oscillates rapidly. The fast end of the spectrum is unchanged.
-
dim 64 completes about 2 full cycles in 1000 positions. Slow enough to carry meaningful long range information, fast enough to differentiate positions.
-
dim 96 does not even complete one cycle. The curve rises smoothly across the entire visible range. This dimension can distinguish between position 100 and position 800 because the values are different.
-
dim 127 is nearly flat. The value barely changes from 0 to 0.1 across 1000 positions. This is the slowest end of the spectrum.
The spread is right. Fast dimensions stay fast. Slow dimensions actually get slow. Every position in a 1000 token sequence gets a unique vector across the full encoding.
Base = 100 million (bottom row)
Now look at what happens when the base is too large.
-
dim 0 still oscillates rapidly. The fast end never changes with base.
-
dim 64 is nearly a straight line. The wave has been stretched so far that it barely changes across 1000 positions.
-
dim 96 is completely flat at zero.
-
dim 127 is also completely flat at zero.
Most of the dimensions are useless. Their values are essentially the same across every position. They contribute no information about where a token is.
A base of 100 million spreads the frequency spectrum too widely. Almost the entire encoding is squeezed into the very slowest dimensions, which do nothing for typical sequence lengths.
The Problem
A smaller base, like 100, would cause the slow waves to repeat much sooner. Different positions would start getting identical encodings. The model would lose the ability to tell them apart.
A larger base, like a million, would spread the frequencies too thin. Most dimensions would oscillate too slowly to be useful.
The value 10000 was chosen to balance these two concerns. It is large enough to avoid repetition within typical context lengths, but not so large that the frequency spectrum becomes useless.
So Far, So Good
We now have a smooth multi frequency encoding. Every position gets a unique vector. The values are bounded between -1 and 1. The transitions between adjacent positions are continuous.
This is already a complete positional encoding. We could stop here and use just sine waves.
But the original Transformer paper does not stop here. Half of the dimensions use sine. The other half use cosine.
Why? What does cosine give us that sine alone does not?
Why Both Sine and Cosine?
We have a working positional encoding using only sine waves. Each position gets a vector. The values are bounded and smooth. The frequencies span from fast to slow.
So why does the original Transformer paper use sine for half the dimensions and cosine for the other half?
The formula assigns sine to even indexed dimensions and cosine to odd indexed dimensions:
\[PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d}}\right)\] \[PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d}}\right)\]Cosine looks redundant. It is just a shifted sine wave. So why include it?
The reason is a property called linear transformability.
Linear Transformability
We want the encoding to have a useful structure.
Given the encoding of one position, we want to reach the encoding of any other position using a simple linear operation.
If we know the encoding at position $pos$, we want to compute the encoding at position $pos + k$ by just multiplying with a matrix. And the same shift should always use the same matrix.
This is a strong property. If it holds, the model can reason about relative shifts using simple linear layers. This matters because $W_q$ and $W_k$ are exactly that, linear layers.
The Pair Representation
Take a single frequency $\theta$. Represent each position as a pair of values, one sine and one cosine:
\[PE(pos) = (\sin(pos\,\theta),\ \cos(pos\,\theta))\]Now, let us ask one question. Can we get from $PE(pos)$ to $PE(pos + k)$ using a fixed matrix?
We can transform using fixed matrix
Write down the encoding at position $pos + k$:
\[PE(pos + k) = (\sin((pos + k)\theta),\ \cos((pos + k)\theta))\]Expand each term using the angle addition formulas:
\[\sin((pos + k)\theta) = \sin(pos\,\theta)\cos(k\theta) + \cos(pos\,\theta)\sin(k\theta)\] \[\cos((pos + k)\theta) = \cos(pos\,\theta)\cos(k\theta) - \sin(pos\,\theta)\sin(k\theta)\]Look at the right hand side. Both new values are built only from $\sin(pos\,\theta)$ and $\cos(pos\,\theta)$. They are scaled by $\cos(k\theta)$ and $\sin(k\theta)$.
This is exactly a matrix multiplication:
\[\begin{bmatrix} \sin((pos+k)\theta) \\ \cos((pos+k)\theta) \end{bmatrix} = \begin{bmatrix} \cos(k\theta) & \sin(k\theta) \\ -\sin(k\theta) & \cos(k\theta) \end{bmatrix} \begin{bmatrix} \sin(pos\,\theta) \\ \cos(pos\,\theta) \end{bmatrix}\]Call this matrix $M_k$:
\[M_k = \begin{bmatrix} \cos(k\theta) & \sin(k\theta) \\ -\sin(k\theta) & \cos(k\theta) \end{bmatrix}\]So we have:
\[PE(pos + k) = M_k \cdot PE(pos)\]The matrix $M_k$ depends only on the shift $k$. It does not depend on $pos$. The same shift always uses the same matrix.
This is the property we wanted.
Why Sine Alone Cannot Do This
Now try the same thing with only sine.
Suppose the encoding is just $\sin(pos\,\theta)$, a single value.
To get the encoding at $pos + k$, we need:
\[\sin((pos + k)\theta) = \sin(pos\,\theta)\cos(k\theta) + \cos(pos\,\theta)\sin(k\theta)\]Look at the right hand side. It needs $\cos(pos\,\theta)$.
But a sine only encoding does not store $\cos(pos\,\theta)$. We only have $\sin(pos\,\theta)$. The term we need is missing.
There is no way to recover $\cos(pos\,\theta)$ from $\sin(pos\,\theta)$ using a linear operation. So the shift cannot be written as a fixed matrix.
The transformation is impossible with sine alone.
Why Cosine Is Needed
Cosine is the missing piece.
When we store both $\sin(pos\,\theta)$ and $\cos(pos\,\theta)$ together, both terms in the expansion are available. The matrix $M_k$ has everything it needs. The shift works.
This is why the encoding pairs sine and cosine at every frequency. It is not redundant. Cosine supplies the second component that makes the linear shift possible.
With both functions present, shifting a position becomes a rotation by the matrix $M_k$.
This rotation idea will come back in a much bigger way when we reach RoPE.
So, this relative information is learned by model implicitly not explicitly
How Sinusoidal Encoding Enters the Model
So far we have studied the positional encoding on its own. We derived its frequencies, its sine and cosine pairing, and its nice properties.
But there is a question we have not asked yet. How does this encoding actually get used inside the Transformer?
The answer creates a hidden problem. The clean properties we discussed do not fully establish once the encoding meets the rest of the model.
Two Properties, Two Places
Before we go further, let’s separate two things we have established.
The first is the dot product property. The dot product of two encodings gives $\cos(\theta(m - n))$, which depends only on relative position. This property matters inside the attention mechanism, where queries and keys are multiplied together.
The second is the linear shift property. A fixed matrix $M_k$ can shift an encoding from one position to another. This property matters for the linear layers in the model, such as $W_q$ and $W_k$.
These are two separate capabilities. They both need sine and cosine, but for different mathematical reasons.
Position Is Added to the Embedding
In the original Transformer, the positional encoding is added directly to the token embedding before anything else happens.
For a token at position $m$:
\[\text{input}_m = \text{embed}_m + PE_m\]The embedding carries the meaning of the token. The encoding carries its position. We add them together into a single vector.
This combined vector is what flows into the attention mechanism. The model then computes queries and keys from it:
\[Q_m = W_q \cdot (\text{embed}_m + PE_m) = W_q \cdot \text{embed}_m + W_q \cdot PE_m\] \[K_n = W_k \cdot (\text{embed}_n + PE_n) = W_k \cdot \text{embed}_n + W_k \cdot PE_n\]Each query and key now has two parts. A semantic part from the embedding, and a positional part from the encoding.
The Four Term Expansion
Now we compute the attention score. The score is the dot product of $Q_m$ and $K_n$.
Both $Q_m$ and $K_n$ have two parts. When we multiply two sums, every part of the first multiplies every part of the second. Two parts times two parts gives four terms.
\[Q_m \cdot K_n = (W_q \cdot \text{embed}_m + W_q \cdot PE_m) \cdot (W_k \cdot \text{embed}_n + W_k \cdot PE_n)\]Expanding gives four terms:
\[\begin{aligned} Q_m \cdot K_n =\ &(W_q \cdot \text{embed}_m) \cdot (W_k \cdot \text{embed}_n) \quad &\text{Term 1}\\ +\ &(W_q \cdot \text{embed}_m) \cdot (W_k \cdot PE_n) \quad &\text{Term 2}\\ +\ &(W_q \cdot PE_m) \cdot (W_k \cdot \text{embed}_n) \quad &\text{Term 3}\\ +\ &(W_q \cdot PE_m) \cdot (W_k \cdot PE_n) \quad &\text{Term 4} \end{aligned}\]Let us read each term.
-
Term 1 is purely semantic. It is the meaning of token $m$ against the meaning of token $n$. No position involved.
-
Term 2 is a cross term. The meaning of token $m$ against the position of token $n$. Semantic mixed with position.
-
Term 3 is the other cross term. The position of token $m$ against the meaning of token $n$. Position mixed with semantic.
-
Term 4 is purely positional. The position of token $m$ against the position of token $n$. This is the term that contains $\cos(\theta(m - n))$, the clean relative position signal.
The relative position information we worked so hard to derive lives only in Term 4.
The Entanglement Problem
Here is the issue.
The model never sees Term 4 by itself. It sees the sum of all four terms. The clean relative position signal is buried inside a mixture.
Terms 2 and 3 are the troublemakers. They mix semantic content with positional content. They are noise sitting on top of the signal the model actually wants.
The model has to work through this mixture. There is no part of the architecture that isolates Term 4. The model must learn, on its own, how to make use of the relative position signal while ignoring the cross terms.
This creates a heavy burden on $W_q$ and $W_k$. These two matrices must do two jobs at once. They must project semantic meaning into a useful space. And they must preserve the positional structure so the relative position signal survives. Two competing goals, packed into one set of weights.
Absolute Versus Relative Position
There is a deeper issue here.
The encoding $PE_m$ stores absolute position. $PE_5$ is a fixed vector. It means position 5 and nothing else, no matter what sequence it appears in.
But what the model actually wants is relative position. It wants to know that two tokens are 9 apart, not that one is at position 5 and the other at position 14.
Relative position is not stored anywhere. It only appears as a byproduct, inside Term 4, after the dot product is computed. It is never represented directly.
So the model is given absolute positions and asked to figure out relative positions on its own. It can do this, but only by learning. There is no guarantee it learns it perfectly.
Position Is Fused With Meaning
There is one more limitation, and it is structural.
Once we compute $\text{embed}_m + PE_m$, the two parts are added into a single vector. They cannot be pulled apart again. Addition destroys the boundary between them.
Every layer after this point sees one fused vector. It cannot choose to look at only the meaning, or only the position. The two are tangled together for the rest of the network.
Sometimes the model only needs meaning. Sometimes it only needs position. But it cannot separate them. It is stuck with the mixture.
Summing Up the Limitations
Sinusoidal encoding is smooth, bounded, unique, and carries relative position inside its dot product. It was a real step forward.
But it has three weaknesses:
-
Entanglement. Relative position is buried inside a four term mixture. Two cross terms add noise the model must learn to ignore.
-
No direct relative position. The encoding stores absolute position. Relative position only appears as a byproduct of the dot product, never as an explicit representation.
-
Fused representation. Position is added into the embedding and can never be separated. Every later layer is forced to handle the mixture.
All three problems share one root cause. Position is added to the embedding.
What if we did not add position at all? What if, instead of adding a positional vector, we applied position as an operation directly on the query and key?
This is the idea behind RoPE.
Idea 5: Rotary Position Embeddings (RoPE)
Sinusoidal encoding had three problems. All of them came from one decision: position was added to the embedding.
What if we never add position at all?
This is the idea behind RoPE, introduced by Su et al. in 2021. It is the positional encoding used in almost every modern large language model, including LLaMA, Mistral, Gemma, and Phi.
The Design Goal
In sinusoidal encoding, the attention score expanded into four terms. Only one of them carried clean relative position. The other two were noise that mixed meaning with position.
We want something better. We want the attention score to look like this:
\[Q_m \cdot K_n = f(\text{semantics},\ m - n)\]One clean expression. The score should depend on the meaning of the two tokens and on their relative distance $m - n$. Nothing else. No cross terms. No entanglement.
The Key Insight
The problem with sinusoidal encoding was the order of operations.
We added position to the embedding first. Then we multiplied by $W_q$ and $W_k$. Because position was already mixed into the embedding, the multiplication produced cross terms.
RoPE flips the order. It does not touch the embedding. Instead, it lets $W_q$ and $W_k$ do their work first, producing the query and key. Then it applies position directly to those vectors.
In other words: apply position after the projection, not before.
Why This Helps
When position is applied after $W_q$ and $W_k$, those two matrices no longer have to deal with position at all. Their only job is to handle meaning. They project the token embedding into a query or key that captures semantic content. That is it.
Position becomes a separate, independent step. It is applied on top of the query and key as its own operation.
There are no longer two competing goals packed into $W_q$ and $W_k$. The projection handles meaning. The positional operation handles position. Each does one job.
Now the question becomes: what operation should we apply to the query and key to inject position?
The answer is rotation.
The Rotation Operation
Take a query vector. To keep things simple, let’s start with just two dimensions.
\[Q = (q_0,\ q_1)\]This query sits at position $m$. We pick a frequency $\theta$, the same kind of frequency we used in sinusoidal encoding.
To inject position, we rotate this 2D vector by an angle of $m\theta$. The rotation is done with a rotation matrix:
\[\begin{bmatrix} q_0^{new} \\ q_1^{new} \end{bmatrix} = \begin{bmatrix} \cos(m\theta) & -\sin(m\theta) \\ \sin(m\theta) & \cos(m\theta) \end{bmatrix} \begin{bmatrix} q_0 \\ q_1 \end{bmatrix}\]This uses the same sine and cosine values as sinusoidal encoding. But the operation is different. We are not adding anything. We are rotating the vector.
The position $m$ decides how much we rotate. A token at position 1 is rotated by $\theta$. A token at position 2 is rotated by $2\theta$. A token at position 100 is rotated by $100\theta$. The further along the sequence, the more the vector turns.
Writing Out the Rotation
Let us expand the matrix multiplication to see the new values directly.
\[q_0^{new} = q_0 \cos(m\theta) - q_1 \sin(m\theta)\] \[q_1^{new} = q_0 \sin(m\theta) + q_1 \cos(m\theta)\]The new query is a mix of the old components, weighted by sine and cosine of the rotation angle.
The length of the vector does not change. Rotation only turns the vector, it does not stretch or shrink it. The meaning carried by the magnitude stays intact. Only the direction shifts, and the amount of shift encodes the position.
We do the exact same thing to the key vector, using its position $n$:
\[k_0^{new} = k_0 \cos(n\theta) - k_1 \sin(n\theta)\] \[k_1^{new} = k_0 \sin(n\theta) + k_1 \cos(n\theta)\]Now both the query and the key have been rotated by their own positions.
The next question is what happens when we take the dot product of two rotated vectors.
Why Rotation Gives Pure Relative Position
We have rotated the query by its position and the key by its position. Now we take their dot product and see what comes out.
This is the heart of RoPE. The result is clean in a way sinusoidal encoding never was.
Setting Up the Angles
Every 2D vector has a direction, which we can describe with an angle.
Let the query $Q$ point in direction $\alpha$. This angle captures the semantic content of the query, the meaning that $W_q$ produced.
Let the key $K$ point in direction $\beta$. This angle captures the semantic content of the key.
Before any rotation, the dot product of two unit vectors depends on the angle between them:
\[Q \cdot K = \cos(\alpha - \beta)\]The score depends on $\alpha - \beta$, the angle between the two directions. This is the semantic relationship between the query and the key.
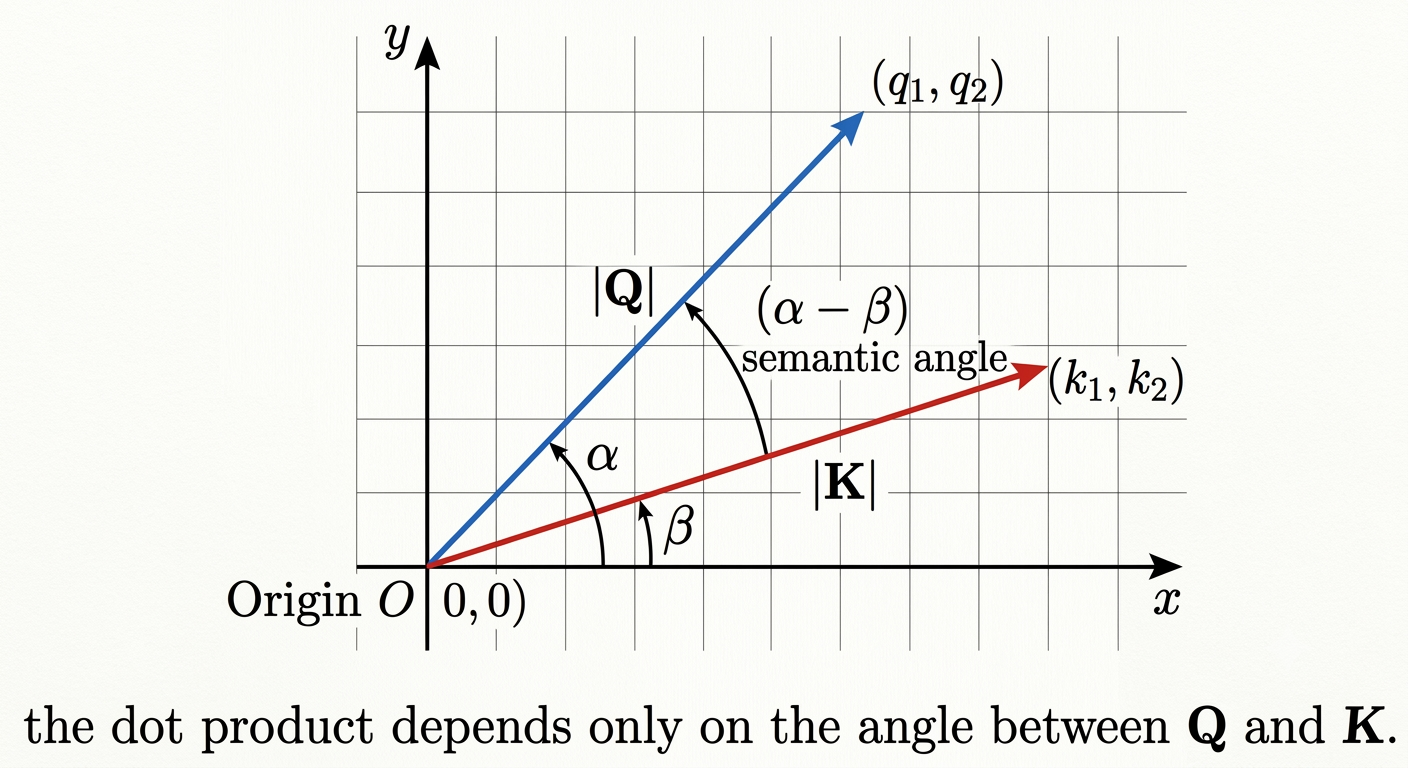
Applying the Rotation
Now we rotate. The query is at position $m$, so we turn it by $m\theta$. The key is at position $n$, so we turn it by $n\theta$.
Rotation simply adds to the angle. After rotation:
\[Q_m \text{ points in direction } \alpha + m\theta\] \[K_n \text{ points in direction } \beta + n\theta\]Take the dot product of the rotated vectors. It depends on the angle between them, just like before:
\[Q_m \cdot K_n = \cos\big((\alpha + m\theta) - (\beta + n\theta)\big)\]Simplify the inside:
\[Q_m \cdot K_n = \cos\big((\alpha - \beta) + (m - n)\theta\big)\]Look at this result carefully.
Reading the Result
There is one term. Just one. No four term expansion. No cross terms.
Inside the cosine there are two pieces:
-
$(\alpha - \beta)$ is the semantic relationship. It is exactly the same angle that was there before rotation. It is untouched.
-
$(m - n)\theta$ is the positional piece. It depends only on $m - n$, the relative distance between the two tokens.
The semantic part and the positional part sit side by side inside a single expression. The meaning is preserved. The position is relative. There is nothing to disentangle.
This is exactly the goal we set at the start. The attention score depends only on the semantics and on the relative distance $m - n$.
The Same Result Through Matrices
The angle argument is good, but let us confirm it with the matrices directly.
Write the rotated query as $R_m Q$ and the rotated key as $R_n K$, where $R_m$ and $R_n$ are rotation matrices. Their dot product is:
\[Q_m \cdot K_n = (R_m Q)^\top (R_n K) = Q^\top R_m^\top R_n K\]Rotation matrices have a special property. They are orthogonal, which means the transpose equals the inverse:
\[R_m^\top = R_m^{-1} = R_{-m}\]So the expression becomes:
\[Q^\top R_{-m} R_n K\]Rotations combine by adding their angles. Rotating by $-m$ and then by $n$ is the same as rotating by $n - m$:
\[R_{-m} R_n = R_{n - m}\]Putting it together:
\[Q_m \cdot K_n = Q^\top R_{n - m} K\]The result depends only on $R_{n - m}$. The absolute positions $m$ and $n$ never appear on their own. Only their difference $n - m$ survives.
This is the same conclusion as the angle argument, now proven through the matrix algebra.
Does Rotation Corrupt Semantic Meaning?
There is a natural objection to all of this. Let us look at it carefully, because initially this is the doubt, I faced initially.
The Concern
The direction of $Q$ encodes the meaning of the token. That is what we said. The angle $\alpha$ carries semantic content.
Rotation changes the direction. After rotation, $Q$ points in a new direction $\alpha + m\theta$.
So if direction is meaning, and rotation changes direction, then rotation must change meaning. Rotation should corrupt the semantic content of the token.
This reasoning feels right. But it has a flaw.
Why the Reasoning Fails
The mistake is in the first step. Meaning in attention is not the direction of a single vector.
What the attention mechanism actually computes is the dot product between a query and a key. And the dot product depends on the angle between them, not on either direction alone:
\[Q \cdot K = \cos(\alpha - \beta)\]The semantic relationship is $\alpha - \beta$. It is a relationship between two vectors, not a property of one.
Now look again at what rotation does:
\[Q_m \cdot K_n = \cos\big((\alpha - \beta) + (m - n)\theta\big)\]The semantic relationship $(\alpha - \beta)$ is still inside the cosine. The rotation only added a positional piece next to it.
The meaning is preserved. It is combined with position, not removed or destroyed.
The Ideal Case
Consider two tokens at the same position, so $m = n$.
The positional piece becomes $(m - n)\theta = 0$. The dot product is:
\[Q_m \cdot K_n = \cos(\alpha - \beta + 0) = \cos(\alpha - \beta)\]This is exactly the original dot product, with no rotation effect at all.
Two tokens at the same position have their full semantic relationship, completely intact. Rotation changed nothing about the meaning.
Rotation Preserves Length
There is another way to see that rotation does not damage the vectors.
Rotation preserves length. A rotated vector has the same magnitude as the original. We can prove this directly.
The squared length of a rotated vector is:
\[|R v|^2 = (R v)^\top (R v) = v^\top R^\top R v\]Since rotation is orthogonal, $R^\top R = I$:
\[v^\top R^\top R v = v^\top v = |v|^2\]The length is unchanged. The magnitude of a query or key often carries learned information too, and rotation leaves it completely unchanged. Only the direction turns.
Where Do the Angles α and β Come From?
We have been talking about the query angle $\alpha$ and the key angle $\beta$. There is a common confusion about what these angles actually are. Let us clear it up.
Not the Embedding Angle
The angle $\alpha$ is not the angle of the token embedding.
Remember the order of operations. First the embedding goes through $W_q$. This produces the query. The angle $\alpha$ is the direction of that query, after the projection.
\[Q = W_q \cdot \text{embed}, \quad \alpha = \text{direction of } Q\]Same for the key. The angle $\beta$ is the direction of $K = W_k \cdot \text{embed}$, after projection by $W_k$.
These angles live in the query and key space. They are not angles in the original embedding space.
Why They Are Different Spaces
The projection matrix $W_q$ is rectangular. It might take a 768 dimensional embedding and produce a 64 dimensional query, one per attention head.
A rectangular matrix does not just rotate the vector. It reshapes it, reweights it, and drops it into a smaller space. The output direction has no simple relationship to the input direction.
So the angle of the embedding and the angle $\alpha$ of the query are not connected in any direct geometric way. The query angle is something new, created by the projection.
Then Why Does (α − β) Carry Meaning?
If $\alpha$ comes out of a projection, why does the angle $\alpha - \beta$ carry semantic meaning at all?
The answer is training.
$W_q$ and $W_k$ are not fixed. They are learned through gradient descent, together with the rest of the model. During training, the loss pushes these matrices to arrange the queries and keys in a useful way.
The arrangement that minimizes the loss is the one where:
-
Tokens that should attend to each other get a small angle $(\alpha - \beta)$. A small angle gives a high cosine, which gives a high attention score.
-
Tokens that should not attend get a large angle $(\alpha - \beta)$. A large angle gives a low cosine, which gives a low attention score.
So the semantic meaning inside $(\alpha - \beta)$ is not inherited from the embedding space. It is learned. Training shapes $W_q$ and $W_k$ until the angle between a query and a key reflects how strongly the two tokens should attend.
The query and key space is built by training to make $(\alpha - \beta)$ mean something. RoPE then rotates within that learned space.
Scaling to Full Dimensions
So far we worked with a 2D query. Real queries have many dimensions, often 64 or 128 per head. How does rotation work there?
The idea is simple. We split the vector into pairs and rotate each pair on its own.
Pairing the Dimensions
Take a query of dimension $d$. Split it into $d/2$ consecutive pairs:
\[(q_0, q_1),\ (q_2, q_3),\ \dots,\ (q_{d-2}, q_{d-1})\]Each pair is a little 2D vector. We rotate each one exactly the way we did before.
The key detail is that each pair gets its own frequency. Pair $i$ uses frequency:
\[\theta_i = \frac{1}{10000^{2i/d}}\]This is the same frequency formula from sinusoidal encoding. Early pairs get high frequencies and rotate fast. Later pairs get low frequencies and rotate slowly.
Each pair is rotated independently. The first pair does not interact with the second pair. There is no mixing across pairs.
The Block Diagonal Matrix
If we write the full rotation as one big $d \times d$ matrix.
It is block diagonal. Along the diagonal sit $d/2$ small $2 \times 2$ rotation blocks, one per pair. Everywhere off the diagonal, the entries are zero.
\[R(m) = \begin{bmatrix} R(m\theta_0) & 0 & \cdots & 0 \\ 0 & R(m\theta_1) & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & R(m\theta_{d/2-1}) \end{bmatrix}\]Each block $R(m\theta_i)$ is the familiar $2 \times 2$ rotation matrix for pair $i$ at position $m$.
Does RoPE Hurt Attention Between Distant Tokens?
The attention score is $\cos((\alpha - \beta) + (m - n)\theta)$. The semantic part and the positional part sit together inside one cosine.
But look closely at those two parts. There is a tension between them.
The Tension
Imagine a paragraph that starts with “Naveen finished the report” and ends, many sentences later, with “He sent it to the team.” The word “He” refers back to “Naveen.” For the model to understand the sentence, the query for “He” must attend to the key for “Naveen.” Suppose these two words are 34 tokens apart.
The model wants them to attend. So the semantic angle $(\alpha - \beta)$ is small, which pushes the cosine up toward a high score.
But the positional part $(m - n)\theta$ is not zero. The tokens are far apart, so this term adds a real angle on top of the semantic one.
The two parts pull in different directions. The semantic angle wants the score high. The positional angle pushes the total angle up, which pulls the cosine down.
When the gap is large, the positional part can fight against the semantic signal. Does the position term quietly suppress attention between tokens that should be linked?
Why It Is Fine at Normal Distances
The answer is the frequency spectrum, and we already have the pieces.
The slow pairs have a tiny frequency. At a gap of 34, the extra angle they add is almost nothing:
\[0.0001 \cdot 34 \approx 0.0034 \text{ radians} \approx 0.2^\circ\]That is a fifth of a degree. The positional part barely moves the cosine in the slow pairs.
And we saw that training pushes the long range signal exactly into those slow pairs. So the “He to Naveen” link lives where the positional cost is nearly zero. The semantic signal wins easily.
Multi head attention helps too. Different heads have their own $W_q$ and $W_k$. Some heads specialize in long range links and lean entirely on the slow pairs. The model has dedicated mechanism for exactly this case.
So at sentence and paragraph distances, the tension is real but harmless. The design routes long range signals to where position does not interfere.
Where It Genuinely Breaks
Now push the gap much further. Not 34 tokens. Try 32000 tokens.
Even the slow pairs have a small but nonzero frequency. Multiply it by a huge gap and the angle is no longer small:
\[0.0001 \cdot 32000 \approx 3.2 \text{ radians} \approx 183^\circ\]Now the slow pair has rotated past 180 degrees. And past 180 degrees, the cosine is negative.
A negative cosine means the contribution is now opposite. The slow pair, which was supposed to carry the long range signal, is now pushing the score down. The model is being told to push these two tokens apart, even though they may be strongly related.
This is not the model being confused about distance. It is worse. The positional term has actively flipped and is working against the right answer.
This is a real, known limitation of RoPE. It is why so much research goes into extending RoPE to longer contexts.
What Happens When Rotation Passes 360 Degrees
The 180 degree problem points to a deeper issue. Rotation is periodic. Turn far enough and you come back to where you started. Let us look at what that means for position.
The Aliasing Condition
Cosine repeats every 360 degrees, or $2\pi$ radians. So two different gaps can produce the exact same cosine.
For a pair with frequency $\theta_i$, two gaps $g_1$ and $g_2$ give the same value when their difference completes a full number of turns:
\[(g_1 - g_2) \cdot \theta_i = 2\pi \cdot k\]for some whole number $k$. When this happens, the two gaps are indistinguishable in that pair. This is called aliasing.
Aliasing in Each Band
Fast pairs alias quickly. With frequency near 1, the gap repeats about every 6 tokens. Gap 1 and gap 7 look almost the same to a fast pair.
This may not seem good, but it is fine. Fast pairs are only meant for short range precision. They do their job locally and we never care them for long distances.
Slow pairs alias very slowly. With frequency near 0.0001, they do not repeat until about 62832 tokens. Within any normal context, they never alias.
So each band repeats at its own distance. Fast pairs repeat every few tokens. Slow pairs repeat only after tens of thousands.
Why the Spectrum Saves Us
Here is the beautiful part. A single pair aliases often. But the full set of pairs almost never aliases all at once.
For two gaps to be truly indistinguishable, they would have to alias in every pair at the same time. That means their difference would have to be a whole number of turns for the fast period, the medium period, and the slow period, all together.
So even though every pair aliases on its own, the combination of all pairs gives each gap a unique fingerprint.
The Real Danger Is Not Aliasing
Aliasing means the model confuses two distances. That is not good, but there is something worse, and we already saw it.
When a slow pair rotates past 180 degrees, its cosine turns negative. The model is not just confused now. It is actively pushed the wrong way. A pair that should support a long range link instead fights it.
This is the precise failure that appears at very long contexts. It is the structural reason that standard RoPE struggles past its trained context length, and the reason researchers built methods to go beyond it further.
Wrapping Up
Let us revise and see the whole journey.
We started with the simplest idea, adding the raw position number, and watched it fail on scale. We normalized it and it failed on consistency. We moved to binary vectors and found a beautiful multi frequency structure, but the jumps between positions broke smoothness.
Sinusoidal encoding fixed the smoothness. It gave every position a unique, bounded, smooth vector, and its dot product quietly carried relative position. But adding it to the embedding entangled position with meaning and forced the model to untangle four terms.
RoPE fixed the entanglement. By rotating the query and key instead of adding to them, it made the attention score depend cleanly on the semantic angle and the relative distance, with no cross terms. It preserved meaning, preserved length, and spread position across a spectrum of frequencies that the model learns to use, fast pairs for nearby tokens and slow pairs for distant ones.
But at very long distances the slow pairs eventually rotate too far, the cosine flips, and attention is pushed the wrong way. That limit is exactly what modern long context research works to mitigate the issue.
But for the sequence lengths that today’s models are trained on, RoPE is clean, efficient, and effective. That is why it used inside almost every modern large language model, from LLaMA to Mistral to Gemma to Phi.
References
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., Polosukhin, I. (2017). Attention Is All You Need. arXiv:1706.03762
-
Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., Liu, Y. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864
-
Biderman, S., Black, S., Foster, C., Gao, L., Hallahan, E., He, H., Wang, B., Wang, P. (2021). Rotary Embeddings: A Relative Revolution. EleutherAI Blog. blog.eleuther.ai/rotary-embeddings
-
Fleetwood. You could have designed state of the art positional encoding. fleetwood.dev/posts/you-could-have-designed-SOTA-positional-encoding